
Kaum eine Technologie wirft bei Versicherern aktuell so viele Fragen auf wie KI, Künstliche Intelligenz. Doch was ist beim Einsatz von KI in der Praxis zu beachten? Ein Gespräch mit Christopher Helm, Gründer & Geschäftsführer der Helm & Nagel GmbH aus Aßlar.
Führungskräfte// 19. November 2021

Christopher Helm, Helm & Nagel GmbH
KI wird häufig definiert als die Befähigung von Maschinen zum menschenähnlichen Denken, Handeln und Entscheiden. Damit bietet KI zahlreiche, vielversprechende Möglichkeiten, um menschliche Fertigkeiten zu skalieren, um die Prozessautomatisierung voranzutreiben und Wettbewerbsvorteile zu sichern.
Auf dem Weg zum digitalen Versicherungsunternehmen gewinnen datengetriebene Prozesse und der Einsatz von Künstlicher Intelligenz immer mehr an Bedeutung. Eine konsequente Entwicklung: Verfügen Versicherer doch über eine Vielzahl an Daten, mit denen von der Risikoprüfung über die Policierung bis hin zum Kundenservice oder der Leistungsprüfung viele Bereiche transformiert werden können.
Welches Verständnis von KI haben Vorreiter in der Branche?
Für KI braucht es nicht nur Algorithmen, sondern auch die Kompetenz der Fachbereiche diese zu befähigen. Vereinfacht dargestellt umfasst die Befähigung von Maschinen zwei Elemente: Einerseits grundsätzlich die Fähigkeit von Algorithmen, Menschen zu imitieren und zweitens den Lernprozess, konkrete Fertigkeit von Menschen zu erwerben.
Gerade durch die jüngste Forschung im Bereich Deep Learning sind Algorithmen fähig, das menschliche Sehen, Hören oder Sprechen zu imitieren. Im Praxiseinsatz benötigt KI jedoch spezialisierte Fertigkeiten. Während bei Menschen eine Fertigkeit einen erlernten oder erworbenen Anteil des Verhaltens bezeichnet, bedeutet dies übertragen auf die KI, dass die KI spezialisierte Fertigkeiten erlernt und so z. B. Aufgaben in der Risikoprüfung übernehmen kann bei denen diese Fertigkeiten benötigt werden.
Anders als bei Lehrlingen, die sich Fertigkeiten zum Beispiel durch die Einweisung ihrer Ausbilder:innen aneignen, benötigt die KI Daten, um Fertigkeiten zu erlernen. Was oft vergessen wird: Damit die KI die Daten nutzen kann um Fertigkeiten zu erlernen, müssen diese vom Fachbereich zunächst aufbereitet werden. Diese Phase der Datenaufbereitung wird von Experten, sogenannten „Data Scientists“, häufig als „Annotieren“ bezeichnet und das dann folgende, überwachte Lernen stellt das eigentliche „Training“ der KI dar.
Die Risikoprüfung als ein Anwendungsbereich für KI bei Versicherern
Bevor KI eigenständig über Annahme oder Ablehnung einer (Vor-)Anfrage entscheiden kann, sammeln (Rück-)Versicherer Daten-Beispiele für Ablehnungen, Aufschläge und Annahmen in Form von Dokumenten. Dazu zählen u. a. Risikovoranfragen, Arztbriefe und Testergebnisse.
Diese Dokumente enthalten Informationen wie z. B. das Alter, die berufliche Tätigkeit, die ausgeübten Sportarten, die Entwicklung des Gesundheitszustands und viele weitere Risikomerkmale der Antragsteller:innen.
Um die KI zu trainieren, werden diese Informationen in Dokumenten zunächst von den menschlichen Experten manuell gesucht, markiert und ergänzend zu Konzepten wie der Diagnose, Beschwerde oder der Therapie zugeordnet.
Diese fachliche Zuordnung der Informationen in den Dokumenten, die Annotationen, bilden die Basis für das Training der KI. Nur durch sie kann die KI lernen, Informationen in neu eingehenden Dokumenten automatisch zu suchen, zu markieren und fachlich einzuordnen; um am Ende – sofern fachlich gewünscht – sogar die Entscheidung über Annahme oder Ablehnung zu treffen.
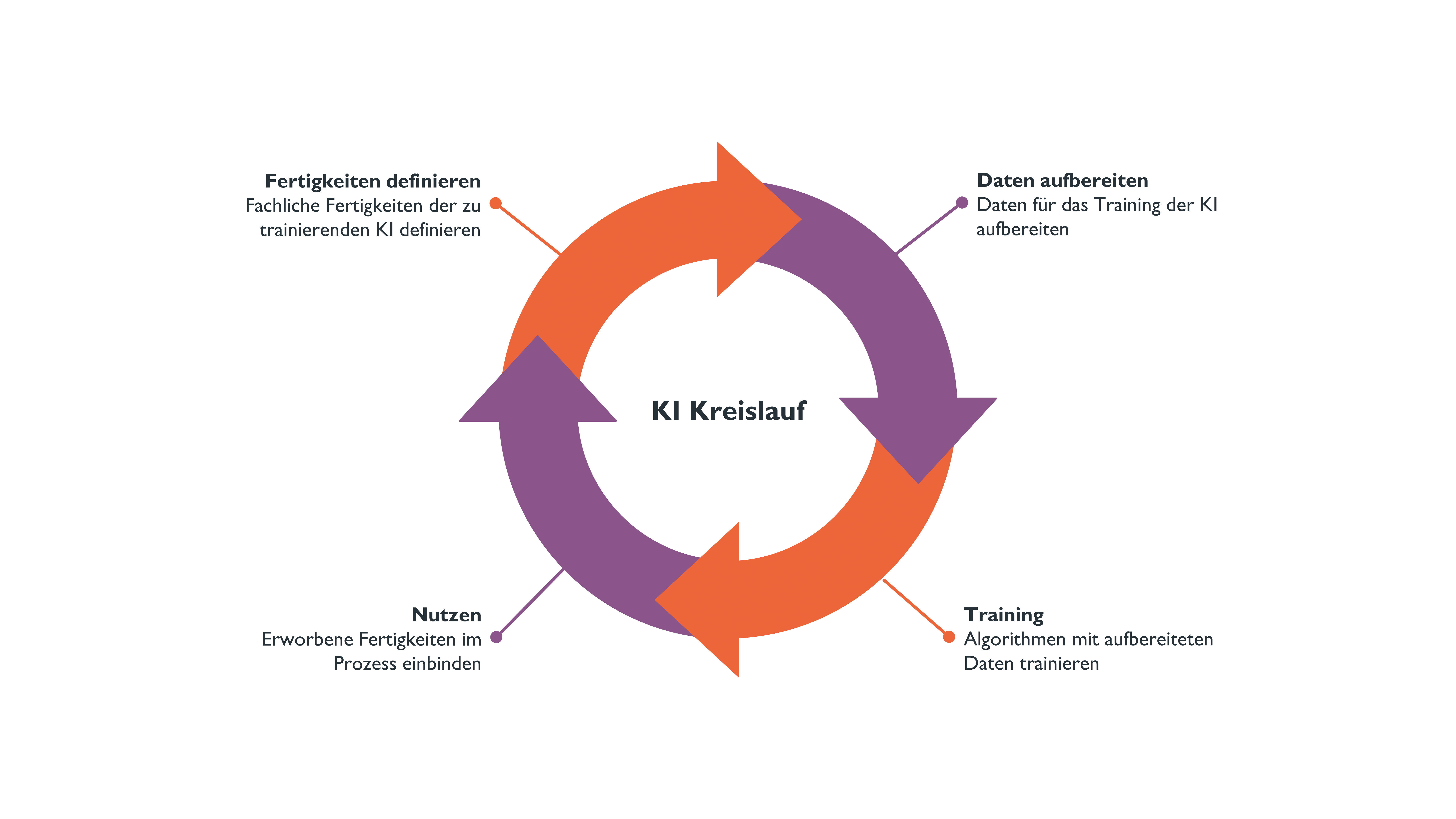
© Helm & Nagel GmbH, 2021 (→ größere Ansicht)
Wie hoch sind die Kosten für KI und wo entstehen diese?
In der Praxis wird häufig angenommen, dass KI beliebige Daten nutzen kann, um zu lernen. Unterschätzt werden die Kosten und Aufwände für die Aufbereitung der bei Versicherern verfügbaren Daten für die KI. Die für die Aufbereitung der Daten benötigten Ressourcen sind um ein Vielfaches höher als die des KI Trainings. Neueste KI-Software bietet zwei Möglichkeiten diesen Kostentreiber zu reduzieren.
„Verfügbare Daten fachlich korrekt für die KI aufzubereiten ist der wichtigste Schritt beim KI-Einsatz in der Praxis“, sagt Christopher Helm, Geschäftsführer der Helm & Nagel GmbH und führt weiter aus: „Fachkräften fehlt häufig die Erfahrung, in welcher Form verfügbare Daten aufbereitet werden müssen um für das Lernen von KI nützlich zu sein.“.
Um die Qualität von Annotationen deutlich zu verbessern, können Software-Lösungen wie „Konfuzio“ der Helm & Nagel GmbH unterstützen. „Die intuitive Nutzeroberfläche unterstützt den Fachbereich beim Annotieren und dem Training der KI. Selbst ohne KI-Vorerfahrung erzielen Versicherer KI-Genauigkeiten und Automatisierungsquoten, die ohne die Software nur durch ein separates Projektteam erreichbar sind.“, erklärt Helm.
Welche Faktoren sprechen für Eigenfertigung oder Fremdbezug von KI?
Wer KI nutzen möchte, hat grundsätzlich zwei Möglichkeiten. Vergleichbar mit der „Make“ oder „Buy“-Entscheidung klassischer Software, trainiert man KI entweder selbst oder kauft diese bereits trainiert von einem Anbieter ein.
Christopher Helm: „Ein Vorteil der fertig trainierten KI ist, dass diese ad-hoc genutzt werden kann. Zum Beispiel erkennt unsere bereits trainierte KI für Rechnungen sowohl Bankverbindungen und Einzelpositionen als auch Empfänger und viele weitere Informationen. Hier haben wir bereits die gesamte Vorarbeit geleistet, sodass Kunden Rechnungen für Fährräder, Arztrechnungen, Werkstattrechnungen, Kostennoten etc. damit verarbeiten können. Die KI ist fertig angelernt und automatisiert sofort die Informationsbeschaffung aus Rechnungen. Die Anwendungsfälle reichen von der Policierung von Fahrrad-Vollkasko Versicherungen bis hin zur Leistungsprüfung gemäß der Gebührenordnung für Ärzte“.
Der Vorteil der vortrainierten KI kann jedoch zum Nachteil werden, wenn besondere Fertigkeiten benötigt werden. Bei komplexen Aufgaben ist das Training eigener KI meist sinnvoll. Um eigene KI besonders kostengünstig zu entwickeln, automatisieren jedoch erst wenige KI-Software Hersteller das Annotieren: Hier unterstützt die KI-Software dabei, täglich neu eingehende Daten fachlich zuzuordnen und das manuelle Annotieren durch den Fachbereich sukzessiv zu entkoppeln. „Das automatische Annotieren spart unseren Kunden viel Zeit, um selbst große Datenmengen für die KI aufzubereiten.“, so Helm.
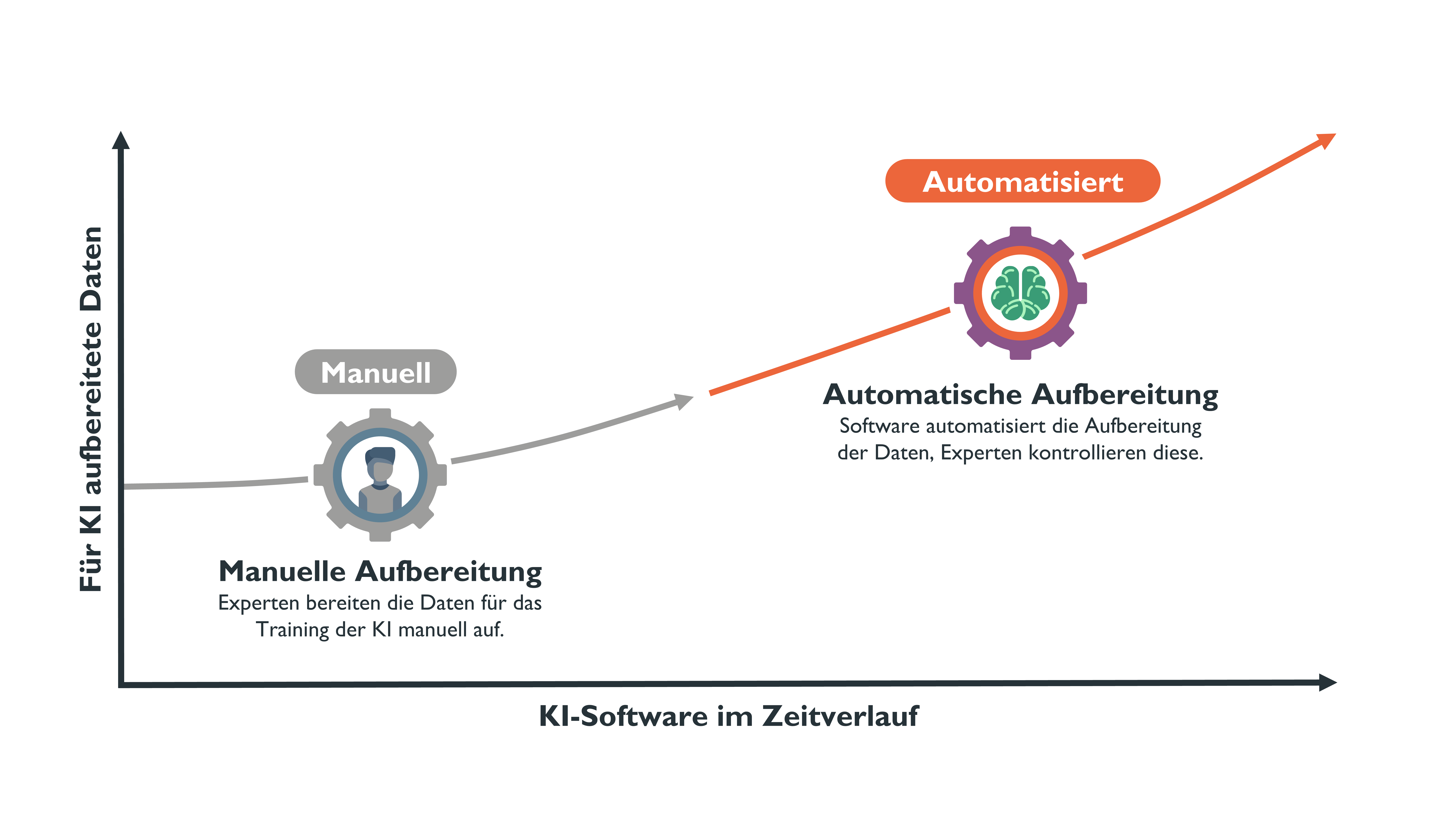
© Helm & Nagel GmbH, 2021 (→ größere Ansicht)
Blockiert der Datenschutz und die Regulatorik die Nutzung von KI?
Seit einigen Jahren ergibt sich aus der Datenschutzgrundverordnung ein noch strengerer Rechtsrahmen für die Nutzung von personenbezogenen Daten. Durch ausgefeilte Löschkonzepte, die – neben dem Hosting in Deutschland oder länderspezifischem Hosting wie häufig in der Schweiz – zu den Grundvoraussetzungen für Deep-Tech Partner gehören sollten, gehen einzelne Unternehmen mit weiteren Optionen zum Schutz der Daten als Branchenprimus voran.
„Auch wenn wir alle Anforderungen für die Datenverarbeitung erfüllen, ermöglichen wir es Großkunden unsere Software selbstständig auf eigenen Servern zu betreiben. Diese Option wird gerade bei der Datenverarbeitung von Berufsgeheimnisträgern, die sonst unter die Regelung § 203 StGB fallen würden, gerne genutzt“, berichtet Christopher Helm und ergänzt: „Dank unserer Kooperation mit der Munich Re lässt sich Konfuzio neben der Wahl des Servers in einer speziell abgesicherten Datenumgebung, dem sogenanntem LAIA Cube, betreiben.“
Zur Person: Christopher Helm ist Gründer und Geschäftsführer der Helm & Nagel GmbH. Durch die Pionierarbeit im Bereich API basierter Plattformen für KI hat das Unternehmen seit Gründung im Jahr 2016 vor allem das Vertrauen stark regulierter Branchen gewonnen. Versicherer, Banken und der öffentliche Sektor haben die Dokumenten KI Plattform Konfuzio bereits heute in diversen Anwendungen integriert.
Letzte Artikel im Bereich: „Azubis“


Letzte Artikel im Bereich: „Führungskräfte“
Letzte Artikel im Bereich: „Podcasts“
Letzte Artikel im Bereich: „Sachbearbeiter“
Letzte Artikel im Bereich: „Vertriebler“
Letzte Artikel im Bereich: „Zukunftsthesen“